
패션 AI를 만드는 옴니어스 리서치팀이 골랐습니다
2018년 한 해가 벌써 마무리되고 있습니다. 눈 깜짝할 새 지나간 열두 달, 인상 깊었던 일을 하나둘 정리하며 내년을 준비 중인 분들이 많으실 텐데요.
올 한 해 AI 분야에서도 많은 일들이 일어났습니다. AI가 전이성 유방암을 진단하고, 채용공고를 검토하기도 했죠. 모두 언급할 수 없을 만큼 다양한 2018년의 AI 관련 이슈들. 그중에서도 옴니어스 팀원들의 시선을 집중하게 했던 인상적인 소식은 어떤 것이 있었을까요? 옴니어스 리서치팀 소속 연구원 윤훈님, 정태님, 형원님, 샤라(Chaharazad)와 CTO 준철님, CEO 재영님에게 물어보았습니다.

(이미지 출처: 세서미 스트리트)
* 각 항목의 순서는 중요도와 무관하며, 본문의 내용은 AI에 대한 전문 지식이 없더라도 쉽게 이해할 수 있도록 작성되었습니다.
1. 사람만큼 자연스러운 전화 예약 : Google Duplex
“Hi, I’m calling to book a women’s haircut for a client.”
올해 5월 공개된 구글 듀플렉스Google Duplex는 사람과 구분되지 않을 만큼 자연스러운 통화로 미용실을 예약해 사람들을 놀라게 했습니다. ‘흠’, ‘어…’ 같은 추임새를 적절히 활용하는 데다 대화 내용에 따른 응답 대기 시간까지 고려한 AI인데요. 예약이라는 주제에 한정된 대화이긴 하지만 실제 사람과 전화로 이야기를 나누는 것만큼 자연스럽습니다.
구글 듀플렉스는 RNN(Recurrent Neural Network, 순환신경망)을 활용해 상대방의 발화 내용을 이해하고 이에 상호작용하도록 만들어졌습니다. 이 기술은 현재 미국 일부 지역에서 테스터에 한해 사용할 수 있도록 공개된 상태입니다. 사람과 분간이 되지 않는다는 지적에 따라 지금은 전화를 걸었을 때 ‘이 전화는 구글에서 걸려온 것이며 녹음될 수 있다’는 안내 메시지를 말하도록 설정되었다고 합니다.
참고자료
→ Google Duplex: An AI System for Accomplishing Real-World Tasks Over the Phone, Google AI Blog
→ 구글 '듀플렉스' 식당 예약 기능 도입…"예약하려고 전화했어요", 아시아경제
2. 구글의 자율주행 택시 서비스 : Waymo
구글의 AI 자율주행 택시 서비스 웨이모 원이 12월 5일부터 서비스를 시작했습니다. 미국 애리조나 주 피닉스 시 주변 160km 반경에서 400명 내외의 고객에 한해 운행 중이고, 승객이 스마트폰 앱에 목적지를 입력하고 웨이모를 호출하는 방식으로 이용할 수 있습니다. 5km 주행에 7.95달러를 받고요.
구글은 2009년부터 자율주행차 프로젝트를 진행해 왔습니다. 매년 전 세계에서 115만 명이 자동차 사고로 사망하며 이 사고 중 94%는 사람의 부주의로 발생하는 것이라는데요. Waymo를 비롯한 자율주행 기술이 이런 사고를 줄여줄 수 있을지, 우리에게 어떤 미래를 가져오게 될지 계속 지켜봐야겠습니다.
참고자료
→ Waymo’s Technology, Waymo
→ 구글 웨이모, 자율주행 자동차에 통신 기술이 더해지다, LG CNS
→ 자율주행 택시 시대 연 웨이모 '일단 합격점', 전자신문
3. 진짜보다 더 진짜 같은 가짜 이미지 : Style-based GAN

(GAN으로 생성된 가짜 사진. 출처: A Style-Based Generator Architecture for Generative Adversarial Networks)
GAN(Generative Adversarial Networks, 생성적 적대 신경망)은 진짜 같은 가짜를 만들 수 있는 딥러닝 알고리즘입니다. 실제 사진을 학습시켜 실존하지 않는 사람들의 사진을 무한대로 만들어낼 수 있고, 저해상도 사진을 고해상도로 만드는 등의 작업도 가능합니다. 2014년 첫 발표 이후 다양한 후속 연구가 이루어지며 시행착오를 거쳐 발전 중인 알고리즘인데요.
이전까지의 GAN이 실제 이미지를 학습해 가짜 이미지를 만들 때 통제할 수 있는 부분이 매우 한정적이었다면, 이번에 NVIDIA에서 발표된 GAN 모델은 이미지의 여러 특징을 인간의 지도 없이 학습해 이를 선택적으로 반영할 수 있습니다. 성별, 나이, 머리 길이, 포즈는 물론 안경을 꼈는지 등 원하는 특징만 골라 적용 가능한데요. 여기에는 NVIDIA의 ‘스타일 믹싱’ 기술이 쓰였다고 합니다.
참고자료
→ GAN 2.0: NVIDIA’s Hyperrealistic Face Generator, Synced(Medium)
→ A Style-Based Generator Architecture for Generative Adversarial Networks, arxiv.org
→ GAN(생성적 적대 신경망), 네이버캐스트
4. 알파고 쇼크를 넘어 알파폴드 쇼크까지? : Deepmind의 AlphaFold
(이미지 출처: AlphaFold: Using AI for scientific discovery)
머신러닝, 딥러닝이 대중에 널리 알려진 데 2016년 알파고 쇼크가 큰 역할을 했죠. 알파고를 개발한 딥마인드는 이제 게임, 바둑을 넘어 과학적 발견을 위한 AI 시스템을 만들었습니다.
인체는 20가지 아미노산으로 수만 가지에서 수십억 가지에 달하는 다양한 단백질을 만들어 냅니다. 근육을 긴장시키는 것부터 빛을 감지하는 데까지 인체의 거의 모든 기능들은 이 단백질의 형태 및 운동에 따라 이루어지죠. 아미노산이 결합할 때 비틀어지고 구부러지는 형태에 따라 단백질의 고유 기능이 생겨나는데요. 단백질이 잘못 접히게 되면 알츠하이머병, 파킨슨병 등을 초래할 수 있습니다. 단백질의 형태를 예측할 수 있다면 치료 방법이 없었던 질병에 맞설 수도 있겠지만 그 경우의 수가 너무 많기에 해결이 어려운 문제였죠.
알파폴드AlphaFold는 심층 신경망(Deep Neural Network)을 통해 방대한 게놈 데이터를 활용, 단백질의 3D 형태를 예측합니다. 올해 12월 2일에 열린 ‘단백질 구조 예측 학술대회(CASP)’에 처음으로 참여해 43개의 단백질 중 25개의 구조를 정확하게 맞춰 98개의 팀 중 1등을 차지했고요. 2등 팀이 3개를 맞춘 것을 참고한다면 2012년 이미지넷 대회가 떠오르는데요. 이미지넷 대회 이후 딥러닝의 전설이 시작된 것처럼 알파폴드가 세상을 뒤바꿀 쇼크를 일으킬 날을 기대해 봐도 좋을 것 같습니다.
참고자료
→ AlphaFold: Using AI for scientific discovery, Deepmind
→ 바둑은 서막...‘알파고’ 생물학판 ‘알파 폴드’에 과학계 쇼크, 조선비즈
→ 구글 딥마인드의 최신병기 알파폴드(AlphaFold), 단백질의 3D 형태 예측, BRIC
5. 인간보다 똑똑한 언어처리 인공지능 시대의 개막: BERT, ELMo, Big Bird
(세서미 스트리트에 등장하는 캐릭터: ELMo, BERT, Big Bird)
2018년엔 이미지/영상 인식은 물론 자연어 처리(NLP, Natural language processing) 분야에서도 많은 발전이 이루어졌습니다. 올해 초 한 논문에서 언어 모델링에 활용할 새로운 기술
ELMo가 등장한 것이 그 시작인데요. ELMo를 통해 학습된 Language Representation을 활용해 여러 NLP task의 학습에 필요한 데이터를 10배 이상 줄일 수 있어 화제가 되었습니다.
이어 지난 11월 구글에서는 언어를 이해하고 주어진 문제에 인간처럼 답할 수 있는 인공지능 언어모델 BERT(Bidirectional Encoder Representations from Transformers)를 공개했습니다. BERT는 자연어 처리(NLP, Natural language processing) 벤치마크 데이터셋이자 NLP 분야에서 이미지넷 대회의 재현이라고 할 수 있는 GLUE와 SQuAD에서 인간에 버금가는 수준의 정확도를 보였는데요. 이는 자연어 처리 AI 발전에 중요한 이정표를 제시했다는 평가를 받고 있습니다.
BERT는 구글의 셀프 어텐션 신경망 모델인 신경망 모델인 트랜스포머Transformer로 구성되어 있습니다. 영어 위키피디아와 BooksCorpus의 33억 단어로 사전 훈련한 모델이 활용되었죠. 기존 Language 모델과 달리 하나의 양방향 모델이 문장의 앞뒤 문맥을 동시에 활용해 의미를 해석할 수 있어 더 높은 정확도를 달성할 수 있게 되었습니다.
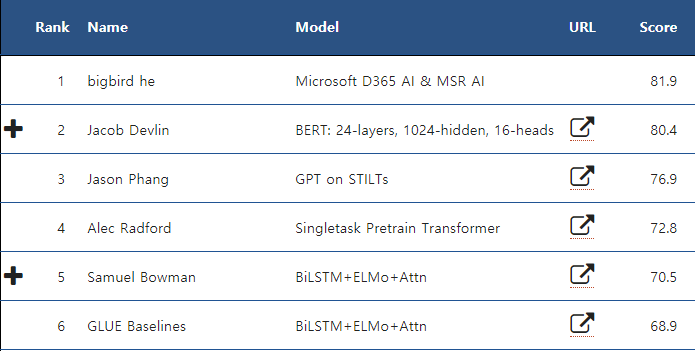
(GLUE Benchmark, 2018. 12. 27일자)
한편 최근에는 MS의 Big Bird가 GLUE 벤치마크에서 BERT를 제치고 1등을 하고 있습니다. 아직 논문은 공개되지 않아 관계자들의 궁금증이 쌓이고 있는데요. NLP의 약진이 사회에 가져올 긍정적인 변화는 매우 다양하지만, 인간 이상의 언어 능력을 지닌 AI가 만들어내는 콘텐츠가 온라인을 점령할 수도 있다는 점은 주의해야 하겠습니다.
참고자료
→ Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing, Google AI Blog
→ The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
, Jay Alammar Blog(Github)
6. 온라인에서도 옷을 ‘입어볼 수’ 있다? : Virtual Try-On

(이미지 출처: VITON: An Image-based Virtual Try-on Network)
패션 아이템은 온라인에서 가장 활발히 거래되는 물품 중 하나입니다. 옷은 꼭 입어 보고 사야 한다는 생각이 이제 많이 희미해진 것 같아요. 하지만 '막상 입어봤더니 나랑 안 어울리는 스타일인 거 아냐?' 등의 고민은 여전히 해결되지 않은 숙제로 남아 결제 버튼을 누르는 데 걸림돌이 되곤 하는데요.
이젠 이런 걸림돌이 사라질 날도 머지않아 보입니다. 가상으로 옷을 입어볼 수 있는 기술이 계속해서 발전하고 있거든요. 옷을 입어볼 사람 이미지에 원하는 옷 이미지를 입히는 모델 학습이 큰 성과를 보이고 있습니다. 해당 모델은 원하는 옷을 사람의 포즈에 맞게 변환하는 모듈과 자연스럽게 옷을 입힌 이미지를 생성하는 encoder-decoder 모듈로 이루어져 있는데요. 특히 기존에 잘 되지 않았던, 원하는 옷의 특징을 잘 보존하는 것이 가능해져 좋은 평가를 받았습니다. 패션 분야에서 AI 기술을 활용하는 것이 이제는 낯설지 않은 일이 되고 있습니다. 패션 이미지 인식 AI로 패션 상품의 속성을 자동 태깅하는 옴니어스 태거도 이중 하나고요:)
참고자료
→ Toward Characteristic-Preserving Image-based Virtual Try-On Network, ECCV 2018
→ VITON: An Image-based Virtual Try-on Network, CVPR 2018
2018년 한 해, 많은 이들을 놀라게 한 AI 이슈들이 있었습니다. 오랜 기간 연구되어 온 기술들이 하나둘씩 놀라운 성과를 보이며 대중과 가까워지고 있는데요. 내년에는 어떤 일들이 일어날까요? 패션 AI 스타트업 옴니어스와 함께 지켜보시죠!





