
옴니어스 데이터 사이언티스트 현진님 인터뷰
이 인터뷰 글에서는
- AI 스타트업 옴니어스의 데이터 사이언티스트, 현진님은 어떤 일을 하시는지
- 현진님이 어떤 툴을 활용해 어떤 데이터를 다루시는지
- 데이터 사이언티스트와 데이터 엔지니어 업무는 어떻게 다른지
등을 알아보실 수 있습니다:)
현진님 안녕하세요! 간단한 자기소개 부탁드립니다.
안녕하세요. 옴니어스에서 데이터 사이언티스트로 일하고 있는 이현진이라고 합니다. 데이터를 통해 사람의 삶을 더 편하고, 보다 효율적으로 만드는 것을 지향하고 있어요.

어떤 계기로 데이터 사이언티스트의 길을 걷게 되셨나요?
저는 이전부터 다양한 일에서 패턴을 찾아내 효율을 높이는 걸 좋아하는 편이었어요. 학교에서 집에 가는 최적 루트를 찾는다던가 하는 자그마한 것을 통해 약간의 효율화를 했을 때도 굉장히 큰 즐거움을 느꼈거든요.
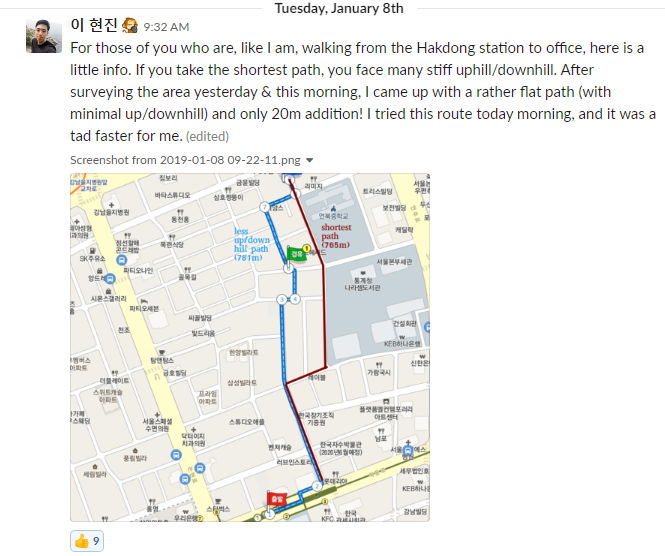
데이터 사이언티스트가 되겠다! 고 구체적으로 생각한 건 한 4~5년 전쯤이었어요. 당시 퍼포먼스 마케터(요즘에는 그로스 해커라고도 부르더라구요)로 일하고 있었는데요. 그때 처음으로 데이터 기반 의사결정 방식을 접하게 되었고, 수치적으로 분석해 의사결정을 내리는 것에 상당한 매력을 느꼈어요.
기존 마케팅은 마케터의 감으로 “A 방식보다 B 방식이 더 좋을 것 같아” 판단하고 진행하던 일이 대부분이었는데요. 퍼포먼스 마케팅에서는 “A/B 테스트 결과를 확인해 보니 B 방식이 A 방식보다 전환율이 약 10% 높다” 와 같이 수치 기반으로 결정을 할 수 있었거든요. 그게 데이터와의 첫 만남이었던 것 같아요.
퍼포먼스 마케터로 다양한 경험을 했지만, 지속적으로 ‘이 일을 보다 효율적으로 할 수 있지 않을까’ 생각했었어요. 예를 들어 성과 보고서를 작성한다면 보고서 양식에 일일이 각 사이트의 성과 수치를 복사해 붙여 넣는 등 일련의 데이터 관리를 모두 사람이 했는데요. 그러다 보니 시간도 오래 걸릴뿐더러 단순 반복 작업을 많이 하다 보면 생기는 집중력 저하로 인한 실수 등이 많았어요. 이걸 어떻게 효율화할까 찾아보다 컴퓨터 공학적 지식이 필요하겠다 싶었고요. 마침 미국에서 데이터 사이언스라는 분야가 막 떠오르던 때였고, 저도 그런 일을 좋아하고 적성에도 맞다고 생각하던 차에 어떻게 보면 시류에 편승하게 되었네요.
데이터 사이언티스트는 어떤 일을 하는 사람인가요?
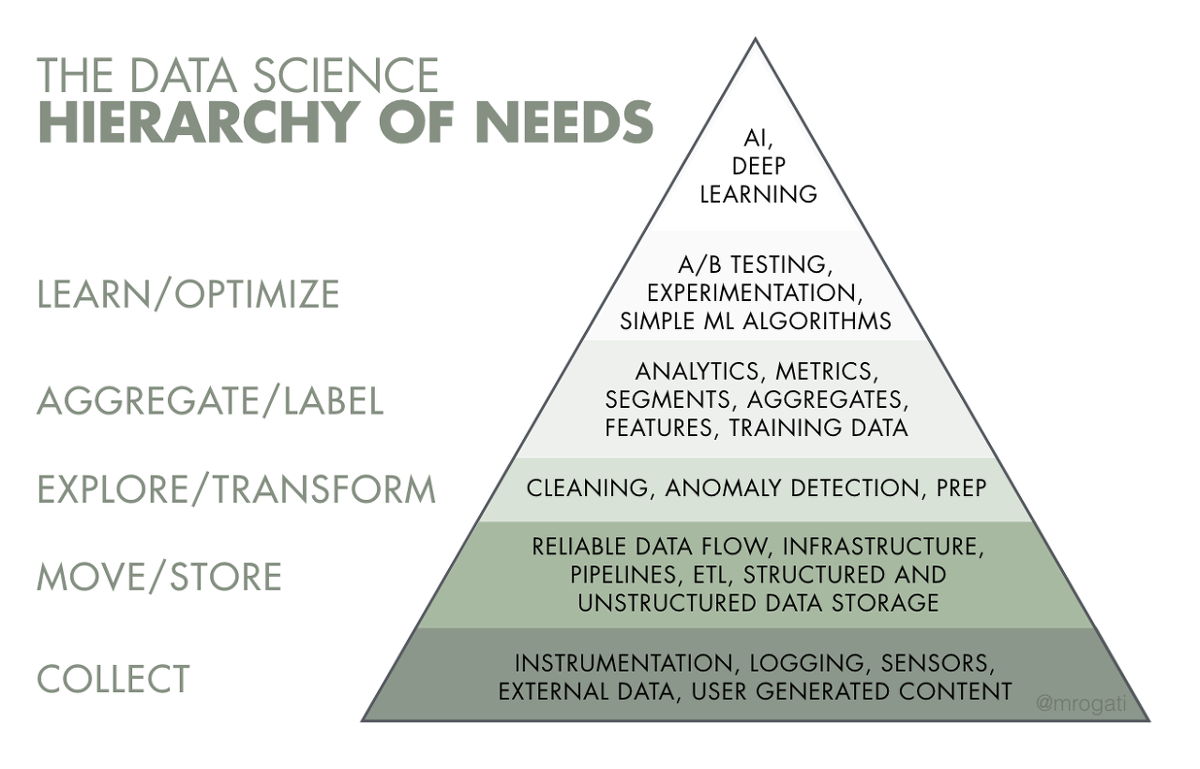
제 일을 설명할 때 예시로 가장 자주 사용하는 그림이에요. 왼쪽 텍스트는 대분류고 오른쪽 피라미드는 그 분류에 해당하는 자세한 업무들입니다. 저는 옴니어스에서 그림의 피라미드 최상단과 최하단을 제외한 나머지 부분에 다 발을 걸치고 있습니다.
최상단 Deep Learning은 저희 AI 제품의 중심이며, Machine Learning Engineer(ML Engineer) 분들이 담당하고 계세요. Computer Vision 관련 경험과 지식이 매우 풍부한 분들께서 보다 나은 AI를 위해 오늘도 고생하고 계십니다. 최하단 Collect는 제품을 직접 개발하시는 개발팀에서 담당하시죠. 저는 나머지 부분, Move/Store 에서부터 Learn/Optimize의 A/B Testing, Experimentation, Simple ML Algorithm까지를 담당 합니다. 물론 중간중간 개발팀 혹은 ML Engineer 분들과 접점이 있는 일도 있어요.
데이터 사이언티스트 업무를 좀 더 자세히 설명드릴게요. 먼저, 데이터를 이용한 메트릭 설정, 관련 실험 설계, 분석이 제 주 업무예요. 우리 비즈니스 전반에 대해 의미 있는 질문들을 던지고, 질문에 답이 될 가설들을 세우고, 어떤 지표를 활용해 모니터링 혹은 확인을 할 수 있는지 설계합니다. 그런 다음 문제를 어떤 방식으로 해결할지 모델링하고 해당 모델링에 필요한 데이터를 어디서 어떻게 얼마나 수집할지, 시간적 여유는 얼마나 있는지, 방법론상 문제점은 없는지 등을 고민합니다. 모델링 중 간혹 필요에 따라 간단한 ML 알고리즘(예를 들면 k-means clustering)이 들어가기도 해요.
하지만 구슬이 서 말이어도 꿰어야 보배라는 말이 있죠. 데이터도 마찬가지예요. 여기저기 흩어져 있는 데이터를 모아 분석에 활용할 수 있도록 꿰어주어야 해요. 그 Data Engineering 작업도 합니다. 쌓여있는 로그 혹은 DB 등의 다양한 데이터 소스로부터 데이터를 추출하고, 이를 분석에 용이한 형태로 각각의 용도에 맞춰 서로 합치거나 변형하는 등의 가공 작업을 진행해요. 가공된 데이터는 쉽게 읽을 수 있도록 데이터 웨어하우스에 적재하는데요. 말씀드린 일련의 작업을 흔히 ETL(Extract, Transform, and Load)이라고 불러요. 그리고 이 작업을 자동화하는 데이터 처리 파이프라인을 만듭니다. 적재 작업 중에 혹시 Data Loss가 있는지, 변형이 잘못된 건 아닌지 정합성도 체크하구요.

옴니어스는 패션 AI 제품을 만드는 회사인데,
여기서 현진님은 주로 어떤 데이터를 다루시나요?
제가 주로 보고 있는 데이터는 3개의 큰 분류로 나눌 수 있을 것 같아요. 첫 번째가 Training Data, 즉 저희 AI가 보고 학습하는 데이터구요. 이 데이터는 해당 데이터의 Bias가 AI 모델의 Bias로 직결되기 때문에 정합성이 매우 중요해요. 예를 들어, 모든 셔츠 데이터는 흰 배경으로 찍고 티셔츠 데이터는 풀밭 배경으로 찍었다면 셔츠-흰 배경, 티셔츠-풀밭 배경이라는 bias가 생길 수 있어요. 그렇다면 셔츠를 풀밭 배경에서 찍었을 때 모델이 데이터의 bias에 의해 이것을 티셔츠라고 오인할 수 있는 여지가 생깁니다.
두 번째는 Product로부터 산출되는 프로덕트 데이터예요. 이 데이터의 경우 저희가 비즈니스와 관련된 인사이트를 뽑아낼 때 활용되고 있습니다. 세 번째는 소셜 네트워크 데이터예요. 특히 소셜 네트워크 데이터의 경우 저희 AI 모델이 기존의 비정형 데이터를 정형화해주기 때문에 완전히 다른 시각으로 접근할 수 있다는 장점이 있어요.
AI 회사에서 다루는 데이터는 다른 회사의 데이터와 어떤 차이가 있나요?
모든 회사가 저마다 다른 데이터를 보유하기에 어떤 차이가 있다고 콕 집어 이야기하긴 어렵네요. 그래도 하나 꼽자면 가장 큰 차이는 앞서 말한 데이터의 세 가지 분류 중 첫 번째, Training Data에 있는 것 같아요. 아무래도 이 데이터가 곧바로 AI에 학습되고, 제품의 핵심이 되는 모델에 바로 영향을 끼치다 보니 다른 데이터보다 훨씬 정합성이 중요한데요. 아무래도 사람의 손을 타는 라벨링 형태다 보니 정합성 확보를 위해서는 추후 데이터를 한번 더 살펴보면서 수정하는 일이 잦아요. 그리고 리서치 팀의 필요에 따라 데이터의 구조도 더 나은 방향으로 지속적으로 변화해요. 이런 다이내믹함이 다른 회사의 데이터와는 다르지 않을까 싶어요.
데이터를 수집/가공할 때 주로 어떤 툴을 쓰시나요?
주로 사용하는 툴로는 Scrapy, Pandas, Pyspark 등이 있습니다.
먼저 데이터 수집 단계에서는 제가 크게 관여하지 않지만, 웹 크롤러를 통해 정보를 얻어야 할 때가 있어요. 그럴 경우 저는 Scrapy를 애용합니다. Scrapy의 경우 다른 것보다 웹 크롤링 전/후 파이프라인 설계를 보다 쉽게 만들어주고, 비동기 방식이라 많은 정보를 크롤 할 때 속도가 빨라서 좋아요.
데이터를 가공할 땐 개인적으로 Pandas를 선호합니다. 예전에는 메모리 누수도 많고 기능도 불완전하다는 부정적인 평가가 많았는데 요즘은 그 부분이 크게 개선되었어요. 초보 고수를 막론하고 쉽게 데이터 가공을 하기 좋은 툴입니다. Pyspark도 간혹 사용하는데, AWS Glue가 Pyspark의 DataFrame 클래스 기반이라 어쩔 수 없는 부분이네요.
추천하는 데이터 분석 툴이 있으시다면?
저는 대부분 Python을 활용해요. 속도도 빠를뿐더러 그 input과 output 구조를 파이프라인화 시키기 편하거든요. 대부분의 기본 통계 도구들은 scikit-learn이나 Scipy의 범위에서 커버가 되구요. 일반 Pearson correlation같이 간단한 것들은 심지어 Pandas의 내장 함수로도 볼 수 있어요. 데이터를 시각화할 때는 Seaborn을 많이 활용하는 편이고, Simulation 문제는 Simpy, Convex Optimization 문제들은 cvxpy로 푸는 편이에요. 다만 특정 통계 기법이 필요하고, 해당 통계 기법이 R에는 이미 안정화된 라이브러리가 있다면 R을 사용합니다. (예를 들면 Fractional factorial design 정도가 있겠네요)
데이터 사이언티스트가 되려면 석/박사를 나와야 하나요?
최근 들어 점점 그렇게 기준이 바뀌는 것 같아요. 1년 전쯤엔 석사 이상의 학력이 우대사항이었다면, 이제는 필수조건에 가까워지고 있거든요. 가끔 예외는 존재하겠지만 현재로써는 석사 이상이 가장 이상적인 조건인 것 같아요. 업무에서 수학이 굉장히 큰 부분을 차지하는데, 통계와 수학 공부를 꾸준히 한다면 회사 내에서 데이터 분석가로 경력을 쌓으면서 데이터 사이언티스트로 커리어를 전환하는 방법도 있을 것 같고요.
데이터 사이언티스트에게 가장 필요한 역량은 무엇이라고 생각하시나요?
가장 필요한 딱 한 가지 역량으로는 비판적 사고(Critical thinking) 능력을 꼽고 싶습니다. 비즈니스와 프로덕트 전반에 대해 의미 있는 질문들을 던지고, 지속적으로 파고들 수 있는 능력이요. 내가 쓸 줄 아는 통계적 툴이 정말 많거나 모델링 실력이 뛰어나더라도 어떤 질문을 해야 할지 모르면 애초에 그 능력들을 활용하기 어려워요. 사실 데이터 모델링이 내가 생각한 대로 진행되는 경우도 드물고요. 그런 상황을 그냥 넘기는 게 아니라 아니라 ‘왜 이렇지?’, ‘이걸 어떻게 확인하고 검증할 수 있지?’를 고민하는 태도가 중요합니다. 물론 통계적 툴도 자유자재로 다룰 수 있으면 금상첨화지만, 저 비판적 사고야말로 실제 가치를 창출하는 데 가장 중요한 것 같아요.
옴니어스에서 데이터 사이언티스트로 일하는 것의 장단점은 무엇이 있을까요?
일하는 데 어려움은 없으신가요?
옴니어스에서 데이터 사이언티스트로 일하는 것의 장점은 여러 가지예요. 가장 크게는 내가 많은 책임을 지는 만큼 유의미한 분석을 할 수 있다는 점이 있고요. 똑똑한 팀원들과 같이 즐겁게 일한다는 것도 큰 이점인 것 같아요. 만들어낼 수 있는 가치가 많다는 점도 매우 좋아요.
다만 제가 분석/실험 업무와 데이터 엔지니어링을 다 함께 하다 보니, 아무래도 절대적인 시간이 부족해요. 파이프라인을 구성하고, 정합성을 확보하고, 유지보수하는 데 공수가 많이 들어가거든요. 이런 부분에 투자된 시간은 그만큼 분석/실험에서 빠지게 되니, 업무 속도를 붙이기 약간 어렵구요.
지금 옴니어스에서는 현진님과 함께할 데이터 엔지니어 분을 채용하고 있죠!
데이터 사이언티스트와 데이터 엔지니어, 직무에 어떤 차이가 있나요?
데이터 엔지니어는 어떤 일을 하나요?
데이터 사이언티스트는 앞서 제가 말씀드린 4단계를 모두 담당하는 반면에, 데이터 엔지니어는 위 그림의 Move/Store에서부터 Transform까지의 두 단계에 집중해요. ETL 파이프라인에 대한 고민, 즉 데이터의 소스로부터 데이터가 온전하게 오는지, 기대한 방식으로 Transform 되는지, loss는 없는지 확인하는 것부터 어떤 식으로 웨어하우스에 데이터를 쌓는 게 좋을지 고민하는 것까지를 맡아하시게 될 거예요.
어떤 데이터 엔지니어를 동료로 맞고 싶으신가요?
아무래도 데이터 쪽은 로직적인 측면이 강한 영역이다 보니, 컴퓨터 공학적 지식이 탄탄하시거나 프로그래밍 능력이 출중하신 분이시면 좋을 것 같아요. 직접적인 ETL 설계 경험은 없으셔도 Dataframe 기반의 Transformation 툴(Pandas, Spark)을 활용해보신 경험이 있으시다면 좋을 것 같고요. 무엇보다도 효율성을 중시하는 분이면 잘 맞을 것 같아요. 어떻게 하면 이 과정을 일반화할 수 있고 보다 효율적으로 개선시킬 수 있는지를 같이 논의할 수 있는 분이면 좋지 않을까 싶어요!





