
딥러닝, 전설의 시작은 알파고가 아니었다
이 글을 읽으면
딥러닝이 무엇인지 & 어떻게 지금처럼 널리 쓰이게 되었는지
비전공자도 쉽고 재밌게 이해하실 수 있습니다:)
이전 편 <왜 요즘 인공지능이 난리죠?> 읽어보시지 않았다면
이 링크를 확인해 주세요!
딥러닝, 전설의 시작은 알파고가 아니었다
언어 번역, AI 스피커, 기업 자소서 검토까지. 요즘은 웬만한 기술에는 다 인공지능이 엮여 있습니다. 인공지능이 이렇게 핫해진 건 2016년 알파고가 바둑으로 세계를 평정한 이후부터였던 것 같은데요. 어떻게 바둑 잘 두는 기술이 이렇게 다양한 일들에 쓰일 수 있는 걸까요?
자료를 조사해보던 저(문과 출신 마케터, 28)는 놀라운 사실을 발견했습니다. 바로 인공지능 열풍의 시작은 사실 알파고, 바둑이 아니었다는 것인데요. 때는 2012년으로 거슬러 올라갑니다.
천하제일 이미지 인식 대회, 이미지넷 챌린지ILSVRC

인간이 습득하는 정보 중 85% 정도는 시각에서 온다고 합니다. 기계에게도 시각 정보를 이해할 수 있는 ‘눈’이 있다면 어떨까요? 우리가 카메라로 사진을 찍고 모니터로 확인하긴 하지만 그 기계들은 화면 속 이미지의 정체가 무엇인지 파악할 능력은 없습니다. 이 능력을 만들어주는 것도 여간 복잡한 일이 아니고요.
컴퓨터에게 고양이를 고양이로 인식하게 하려면 어떻게 해야 할까요? 세상에 존재하는 고양이 개체수는 엄청납니다. 그 많은 고양이들이 만들어낼 기상천외한 자세도 경우의 수가 너무 많아 ‘이것이 고양이다!’ 라고 정의할 수 없었던 거죠. 몇 년 전까지는요.
(털 색이나 자세가 달라도 다 고양이죠!)
2007년 시작된 이미지넷 프로젝트는 컴퓨터에게 이미지를 이해시키는 것, 즉 ‘보는 법’에 대한 연구를 촉진시켜 해결 방안을 찾기 위해 시작되었습니다. 사람의 눈을 카메라 한 쌍이라 치면 3살 때까지 수억 장의 현실 세계 사진을 보는 셈이라는데요. 사람이 이 과정을 거쳐 시각 정보를 받아들이는 걸 학습한 것처럼 컴퓨터에게도 엄청나게 많은 사진을 보여 주며 학습시키면 이미지를 시각 정보로서 받아들일 수 있지 않을까, 그럼 컴퓨터가 볼 사진을 많이 모아야겠네! 하며 시작한 게 이미지넷 프로젝트였습니다.
컴퓨터에게 눈을 달아주는 학습을 위해 이미지넷 프로젝트는 인터넷에서 약 10억 장의 이미지를 구했습니다. 167개국의 5만 명의 작업자가 이 작업에 참여한 결과 2009년에는 객체와 사물을 2만 2천 개 범주로 구분한 1천5백만 장 이미지 데이터베이스를 확보할 수 있게 되었습니다. 고양이 사진만 6만 2천 장이나 있었고요.
이미지넷에서는 이 데이터베이스를 오픈소스로 공개했습니다. 2010년부터는 이 데이터베이스를 바탕으로 이미지넷 챌린지(ILSVRC, ImageNet Large Scale Visual Recognition Challenge)도 진행했는데요. 이미지넷의 데이터 중 일부가 주어지면 해당 데이터가 어떤 물체의 사진인지 맞추는 대회였습니다.

(이미지넷 프로젝트를 시작한 페이페이 리의 TED 강연에서 자세한 이야기를 살펴보실 수 있습니다.)
이미지넷 챌린지에서 2010년에는 오류율 28%, 2011년에는 오류율 26%인 팀이 우승을 차지했습니다. 더 이상의 획기적인 성능 개선은 어려울 거라는 게 주된 의견이었지만 영웅은 난세에 등장하는 법이죠. 2012년에 놀랍게도 작년 우승팀 대비 10%나 오류율이 줄어든 알렉스넷Alexnet이 등장합니다. 혜성같이 등장한 알렉스넷, 그 성능의 비결이 핫이슈였죠. 알렉스넷이 신경망 모델, 흔히들 딥러닝이라고 말하는 모델을 사용한 것이 알려지며 딥러닝의 전설이 시작됩니다.
그럼 딥러닝은 뭐죠?
딥러닝은 저번 글에서 이야기했던 인공신경망의 계보를 잇는 기술입니다. 쉬운 설명을 위해 딥러닝으로 이미지 인식, 번호판 숫자를 읽어내는 기계를 만든다고 가정해 볼게요. 이 경우에 기계가 어떻게 숫자를 구분할 수 있을까요? 구분을 위해 숫자들의 서로 다른 특징을 짚어내 봅시다. 1은 세로 작대기고, 2는 상단에 가로로 둥근 곡선이 있고… 이런 식으로 찾아내는 특징을 피쳐Feature라고 부르는데요.
딥러닝이 아닌 기존의 알고리즘에서는 이 피쳐를 사람이 정의했어요. 숫자 1과 2의 차이는 어떠어떠한 것이다, 하는 식으로요. 하지만 딥러닝에서는 이런 피쳐를 사람이 정의하지 않고 데이터를 모아 통계적인 특성에서 뽑아냅니다. 어떤 특성을 뽑아낼지도 사람이 직접 정해주지 않고요.

(딥러닝에서 계층적으로 표현된 피쳐들을 시각화한 대표적인 그림(Nvidia Slide))
딥러닝은 특성을 찾아내는 데 사람 뇌의 뉴런 구조를 본따 만든 인공 신경망을 활용합니다. 이 인공 신경망의 층이 많아 깊은 것이 ‘딥’ 러닝의 특징이죠. 인공 신경망의 상호 작용으로 피쳐를 구분하는 기준을 스스로 학습하는 건데요. 실제 사람의 뇌에는 1000억 개쯤 되는 뉴런이 있고 그것들이 밀접하게 연결되어 있다잖아요. 세포 하나하나로는 할 수 없던 일들이 세포들의 연결을 통해 가능해지는 것처럼 인공신경망의 연결을 깊게 해 보니 인식이 잘 되더라 하는 거죠.
물론 단순히 인공신경망 층이 많다고 성능이 개선되는 건 아닙니다. 하지만 처음 인공신경망 개념이 나온 이후로 컴퓨터 성능이 좋아지고, 기존의 알고리즘이 가졌던 문제들이 해결되고, 인터넷 등 대량의 학습 데이터를 구할 수 있는 방법이 많아진 덕에 인공신경망의 성능이 좋아지게 되었습니다. 그 과정에서 이미지넷 대회를 뒤집어놓은 성과를 나타낸 딥러닝도 나온 거지요.

(인공신경망과 뉴런 도식화. 인공신경망에 대한 자세한 이야기는 이전 글을 참고해 주세요.)
그래서, 이미지 인식이랑 알파고가 무슨 상관이죠?
이미지넷 챌린지에 참여한 팀들의 알고리즘은 모두 오픈소스로 공개됩니다. 우승팀인 알렉스넷의 알고리즘도요. 딥러닝에 대한 관심이 집중되며 이후 다양한 연구를 통해 성능이 계속해서 개선되고, 새로운 알고리즘 또한 나오게 되었죠. 그 상황에서 2014년 초 구글이 영국의 딥마인드라는 스타트업을 4억 달러라는 거금에 인수합니다.

2010년 설립된 딥마인드는 사업 모델도 마땅히 없었고, 12명의 딥러닝 전문가가 존재할 뿐인 곳이었습니다. 하지만 그 12명이 지구를 통틀어 몇십 명 되지 않는 핵심 연구원들이었다는 게 함정. 사람이 미래였던 거죠. 구글은 2013년 딥러닝 분야의 구루 제프리 힌튼 교수를 영입하는 등 딥러닝에 엄청난 투자를 계속하고 있었고 딥마인드 인수는 그 연장선으로 볼 수 있습니다.
그러고 딥마인드는 게임을 시작했습니다. 흔히 ‘고전게임’ 하면 떠오를 벽돌깨기 등이 포함된 아타리 게임 49종을 사람과 같은 조건에서 학습했는데요. 알렉스넷의 이미지 인식 알고리즘으로 게임 화면을 인식하게 해 사람과 같은 정보만 전달해준 채 게임을 진행하도록 한 겁니다. 어떻게 해야 게임에서 점수를 얻을 수 있는지 알려주고 그 점수를 얻을 방법은 알아서 찾아내라며 학습시킨 건데요. 이 학습 과정에서도 일종의 딥러닝이 활용되었죠. 이 학습이 잘 이루어져서 실제 몇몇 게임은 사람만큼 잘하게 되었습니다.
(영상 : 딥러닝으로 이렇게 게임을 잘하게 됩니다)
2015년 네이처에 강화학습 딥러닝으로 게임을 학습했다는 이 논문이 실리고 1년 후. 아시다시피 딥마인드는 알파고로 전 세계를 놀라게 합니다. 딥러닝은 계속해서 발전해 이미지를 인식하는 것과 바둑을 잘 두게 하는 것을 넘어 현실 세계의 많은 문제들을 해결하고 있습니다.
딥러닝이 할 수 있는 것들
딥러닝으로 바둑만 잘 둘 수 있었다면 인공지능이라는 말이 이렇게 자주 쓰이지 않았을 겁니다. 알파고 이후 계속해서 발전을 거듭한 딥러닝은 앞서 말한 이미지 인식이나 게임은 물론 로봇과 자율주행, 음성인식 등등 다양한 분야에서 활용되고 있습니다.
그림을 넣으면 알아서 채색해주는 Paintschainer도 있고,
영상 속 얼굴을 바꿔치기하는 Deepfake도 신기하고,
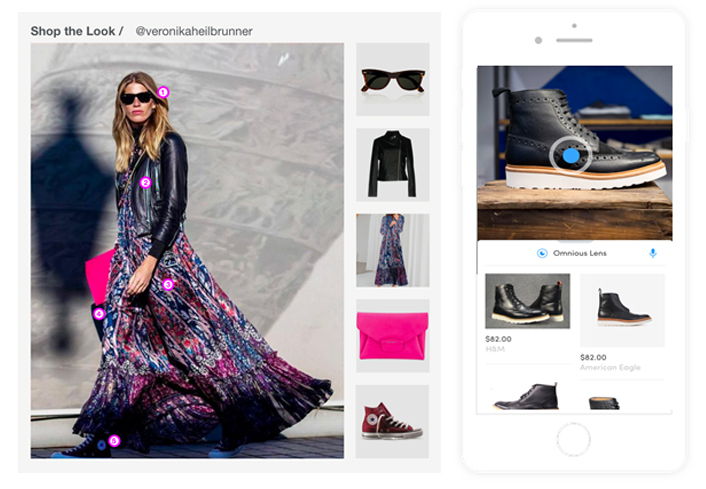
패션 이미지 인식 AI로 패션 아이템을 분석해 주는 우리 옴니어스를 빼놓을 수 없죠.
미국에서는 오는 12월 중 일부 지역에서 무인자동차를 상용화할 예정입니다. 이제 이미지넷의 우승작은 사람보다 이미지를 잘 분류해낼 수 있고요. 인공지능으로 세상이 빠르게 바뀌고 있습니다. 인간이 적응의 동물이라고는 하지만 세상을 바꿀 기술이 어떤 것인지, 세상이 어떻게 바뀌게 될지 미리 알 수 있다면 변화에 적응을 넘어 변화를 활용할 수 있지 않을까요?
<문과생이 털어보는 AI 이야기>를 통해 저 같은 문과생들도 이에 실마리를 구할 수 있길 바라봅니다:)
3줄요약
- 컴퓨터 이미지 인식 대회, 이미지넷 챌린지에서 2012년 획기적인 성능을 가진 우승자 알렉스넷이 등장합니다.
- 알렉스넷이 신경망 모델 aka 딥러닝을 사용한 것이 알려지며 알파고 등등의 딥러닝 전설이 시작됩니다.
- 인공신경망 발전의 3대 요소(컴퓨터 성능의 발전, 대량의 학습 데이터, 알고리즘 개선)가 알파고와 지금의 딥러닝을 있게 해 주었습니다.





